시작하기
Class101의 경우, 로그인 후 "https://class101.net/search?state=sales&types=klass" 접속 시, 현재 시점으로 바로 수강 가능한 강의 목록을 가져 올 수 있다. 하지만 바로 모든 강의가 조회되는 것이 아닌 스크롤링을 아래로 향할때 마다 일정 갯수 만큼 받아 오도록 화면이 구성되어 있다. 따라서, 모든 데이터를 크롤링 하기 위해선 반복적으로 하단 스크롤링을 한 후, 모든 데이터가 조회가 된 후 크롤링 작업을 시작해야 한다.
개발환경
- MAC OS Big Sur 11.2.3
- Python3
- Chrome 버전 90.0.4430.93(공식 빌드) (x86_64)
- Chrome Driver 90.0.44
개발준비
사용한 패키지 및 도구
- selenium, BeautifulSoup, pandas
pip3 install selenium pip3 install BeautifulSoup pip3 install pandas- ChromeDriver 설치 (자신이 로컬에 설치된 Chrome버전과 동일한 버전으로...)

개발내용
소스코드를 확인하기 전에 먼저 어떠한 방법으로 어떠한 데이터를가져올지를 파악해야한다.
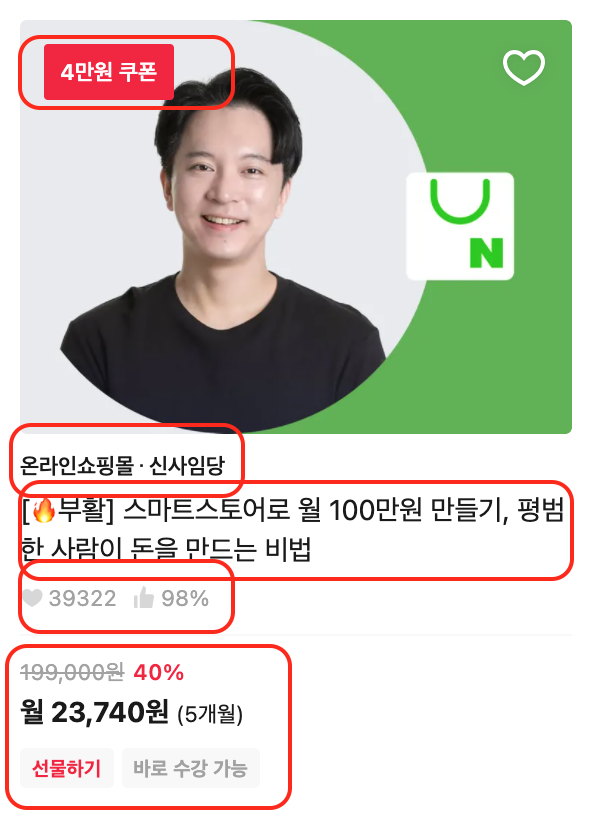
1. 온라인 쇼핑 몰 / 신사임당 : 카테고리 및 강사 명
2. [🔥부활] 스마트스토어로 월 100만원 만들기, 평범한 사람이 돈을 만드는 비법 : 강좌 명
3. [39322] / [98%] : 관심도 및 만족도
4. [월 23,740] / [5개월] : 가격및 기간
5. [199,000] / [40%] : 원가 및 할인률
대략적인 스크롤링 방법을 구상 한 후, 어떠한 데이터를 모일지도 파악완료 했다.ㄱㄱㄱ

참고로 필자는...파이썬 개발자가 아니고... 잠시 일적으로 필요해서... 파이썬으로 해당 프로그램을 작성했다.. 그래서 파이썬의 문법이나 코드가 매끄럽지 못하고 난잡할 수 있다는걸...참고..
전체 PythonCode
from selenium import webdriver
import time
import re
from bs4 import BeautifulSoup
import pandas as pd
# 목표 - class 101에 등록된 모든 강의들의 정보(클래스 명, 카테고리, like, 가격, 정보 등)
# http://class101.net/search?state=sales&types=klass 접속 시, 전체 강의목록을 조회할 수 있다.
# 하지만 스크롤링이 하단에 갈때마다 특정 갯수 만큼 다시 조회를 하는 형식이라서 전체 강의가 완전하게 조회 될때까지 계속해서 하단으로 스크롤링을 해야함
# 따라서 현재 화면의 강의수와 스클롤링 후 화면에 보이는 강의 수가 같아 질떄까지 계속해서 [스크롤링 > 강의 갯수 조회 ] 해당로직을 무한 반복한다.
# 스크롤링 하는 소스 코드
from selenium.webdriver.common.keys import Keys
# bg = driver.find_element_by_css_selector('body')
# bg.send_keys(Keys.SPACE)
import datetime
def doScrollDown(driver):
start = datetime.datetime.now()
end = start + datetime.timedelta(seconds=10)
while True:
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(1)
if datetime.datetime.now() > end:
break
# 현재까지 조회된 class 갯수를 가져 온다.
def getCurrentClassNum(driver) :
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
return len(soup.select('div.sc-citwmv > ul li'))
#classList[0].select('strong.SellingPrice-yffb6l-0')[0].text '월 25,740원' main price
#classList[0].select('span.InstallmentText-v6zzig-0')[0].text ' (5개월)' main date
#classList[0].select('div.CardTags-sc-1fo9d2v-0')[0].text '온라인쇼핑몰・신사임당' categori and 강사명
#classList[0].select('div.sc-dOSReg')[0].text '[🏆BEST특가] 스마트스토어로 월 100만원 만들기, 평범한 사람이 돈을 만드는 비법' MainTitle
#classList[0].select('div.CountTag__Container-rjlblo-0')[0].text '39225' 하트그림 옆에 있는 숫자
#classList[0].select('div.CountTag__Container-rjlblo-0')[1].text '98%' 따봉 수
#classList[0].select('span.OriginalPrice-fb3m0l-0')[0].text '199,000원' original price
#classList[0].select('span.DiscountPercent-sc-1phvwfl-0')[0].text '35% ' discount rate
def makeClassData(driver) :
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
classList = soup.select('div.sc-citwmv > ul li')
numOfClass = len(classList)
classData = ' '
data = []
for i in range(numOfClass) :
classData = classList[i]
try:
categoriAndLecturer = classData.select('div.CardTags-sc-1fo9d2v-0')[0].text #'온라인쇼핑몰・신사임당' categori and 강사명
categori = categoriAndLecturer.split('・')[0]
lecturer = categoriAndLecturer.split('・')[1]
except:
categori = ''
lecturer = ''
try:
mainTitle = classData.select('div.sc-dOSReg')[0].text #'[🏆BEST특가] 스마트스토어로 월 100만원 만들기, 평범한 사람이 돈을 만드는 비법' MainTitle
except:
mainTitle = ''
try:
mainPrice = classData.select('strong.SellingPrice-yffb6l-0')[0].text # '월 25,740원' main price
except:
mainPrice = ''
try:
period = classData.select('span.InstallmentText-v6zzig-0')[0].text # ' (5개월)' main date
except:
period = ''
try:
attention = classData.select('div.CountTag__Container-rjlblo-0')[0].text # '39225' 하트그림 옆에 있는 숫자
except:
attention = ''
try:
satisfaction = classData.select('div.CountTag__Container-rjlblo-0')[1].text # '98%' 따봉 수
except:
satisfaction = ''
try:
originalPrice = classData.select('span.OriginalPrice-fb3m0l-0')[0].text #'199,000원' original price
except:
originalPrice = ''
try:
discountRate = classData.select('span.DiscountPercent-sc-1phvwfl-0')[0].text # '35% ' discount rate
except:
discountRate = ''
data.append([categori, lecturer, mainTitle, mainPrice, period, attention, satisfaction, originalPrice, discountRate])
return data
#스크롤링 3번하자`
def scrollDown(bg) :
bg.send_keys(Keys.SPACE)
bg.send_keys(Keys.SPACE)
bg.send_keys(Keys.SPACE)
bg.send_keys(Keys.SPACE)
bg.send_keys(Keys.SPACE)
bg.send_keys(Keys.SPACE)
#https://class101.net/search?state=sales&types=klass
# 전체 수강 강좌 조회 사이트 열기.
driver = webdriver.Chrome("./chromedriver")
driver.get('http://class101.net/search?state=sales&types=klass')
bg = driver.find_element_by_css_selector('body')
# 현재 화면 html 정보 가져오기
#html = driver.page_source
#soup = BeautifulSoup(html, 'lxml')
# 강좌 정보 list 가져 오는 값
# soup.select('div.sc-citwmv > ul li')
currentNum = getCurrentClassNum(driver)
afterNum = 0
while(1) :
doScrollDown(driver)
afterNum = getCurrentClassNum(driver)
if currentNum == afterNum :
break
else :
currentNum =afterNum
print(currentNum)
result = makeClassData(driver)
result = pd.DataFrame(result)
result.to_csv('/Users/kimyoungho/python/class.csv', index=False, encoding="utf-8-sig")
print(result)
간략하게 로직을 설명하자면...
1. ChromeDriver를 통해 Chrome실행 후, Class101 접속
2. 현재화면의 나타난 강의들의 목록을 찾고 갯수를 센다.
# 현재까지 조회된 class 갯수를 가져 온다.
def getCurrentClassNum(driver) :
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
return len(soup.select('div.sc-citwmv > ul li'))3. 하단으로 10초동안 스크롤링을 반복한다.( 이때, 강의 목록이 추가적으로 더 불러 오게 됨.)
def doScrollDown(driver):
start = datetime.datetime.now()
end = start + datetime.timedelta(seconds=10)
while True:
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(1)
if datetime.datetime.now() > end:
break4. 이전의 샌 갯수와 조회 후 갯수를 비교한다. 하단 스크롤링 후 샌 갯수가 더 많다면 위 과정을 반복한다.
5. 만약 스크롤링 후에도 이전의 갯수와 스크롤링 후의 갯수가 같다면 더이상 조회할 강의가 없다는 뜻임으로... 크롤링으로 데이터를 수집 후 종료 한다.
currentNum = getCurrentClassNum(driver)
afterNum = 0
while(1) :
doScrollDown(driver)
afterNum = getCurrentClassNum(driver)
if currentNum == afterNum :
break
else :
currentNum =afterNum
print(currentNum)
실행결과
실행 결과로 나온데이터로 아직 어떠한 유의미한 작업을 하지 않은 상태라 날것의 데이터 그대로가 있다. 작업을 하기 전에 이러한 데이터에서 어떤유의미한 결과를 도출해야 하는지 파악해야 하는데..이게 쉽지 않다. 그래서 저번 파이썬 크롤링때 처럼 워드클라우드라던가..하는건 추후에 올리도록 하겠다.
(뭔가...크롤링한 결과 여기다가 올리면 안될거 같아...알아서...하쇼...)
마무리
Python 문법도 재대로 모르는 놈이 파이썬으로 이것저것 크롤링을 하고 있는데... 나름..점점 재밌어 지고 있다.. 잡탕개발자의 길을 걷는듯..

인스타그램 크롤링 작업을 하면서 고생을 좀 많이 해서인가.. 이번 프로그램은 3시간정도 걸린거 같다. 크롤링 하는 방식도 단순하고 한번에 모든 강의를 조회할 수 있는 페이지가 있어서 정말 편한듯 ㅇ.ㅇ...
다음은 "탈잉" 사이트 크롤링 작업을 해볼 생각이다. 대충 화면 봤는데...난이도가 상당해 보이는게 벌써 망삘이 ...ㅠㅠ
'개발 > Python' 카테고리의 다른 글
| [Python] Taling.me Crawling (0) | 2021.05.18 |
|---|---|
| [Python] Instagram Crawling (0) | 2021.05.13 |