[Python] Taling.me Crawling
시작하기
첫시도
Taling(https://taling.me)을 접속하면 놀랍게도 등록된 클래스들을 전체적으로 조회 할 수 있는 메뉴가 존재 하지 않았다.
그래도 희망을 가지고 해당 사이트를 분석을 해보았다.
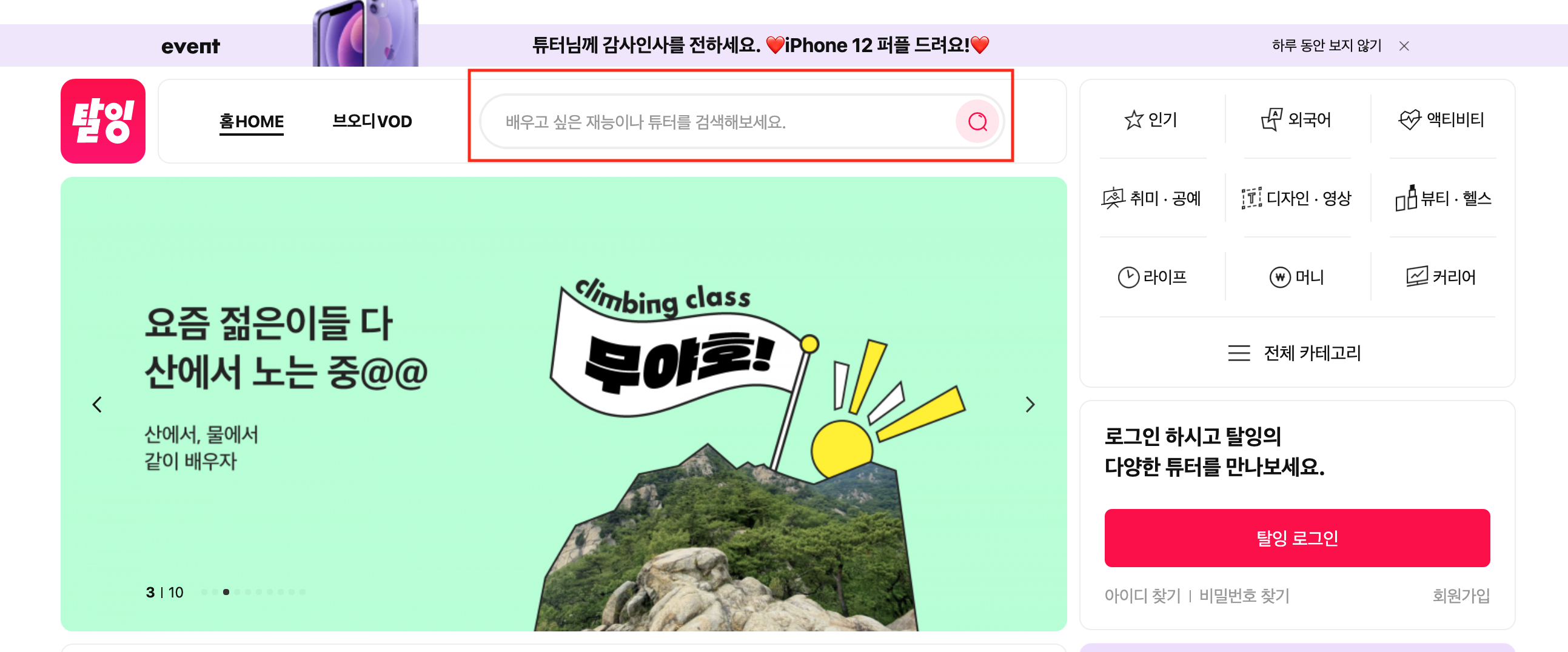
먼저 메인 페이지에 접속해서 해당 네모칸에 검색어를 넣으면 검색된 강의들이 나오는데...
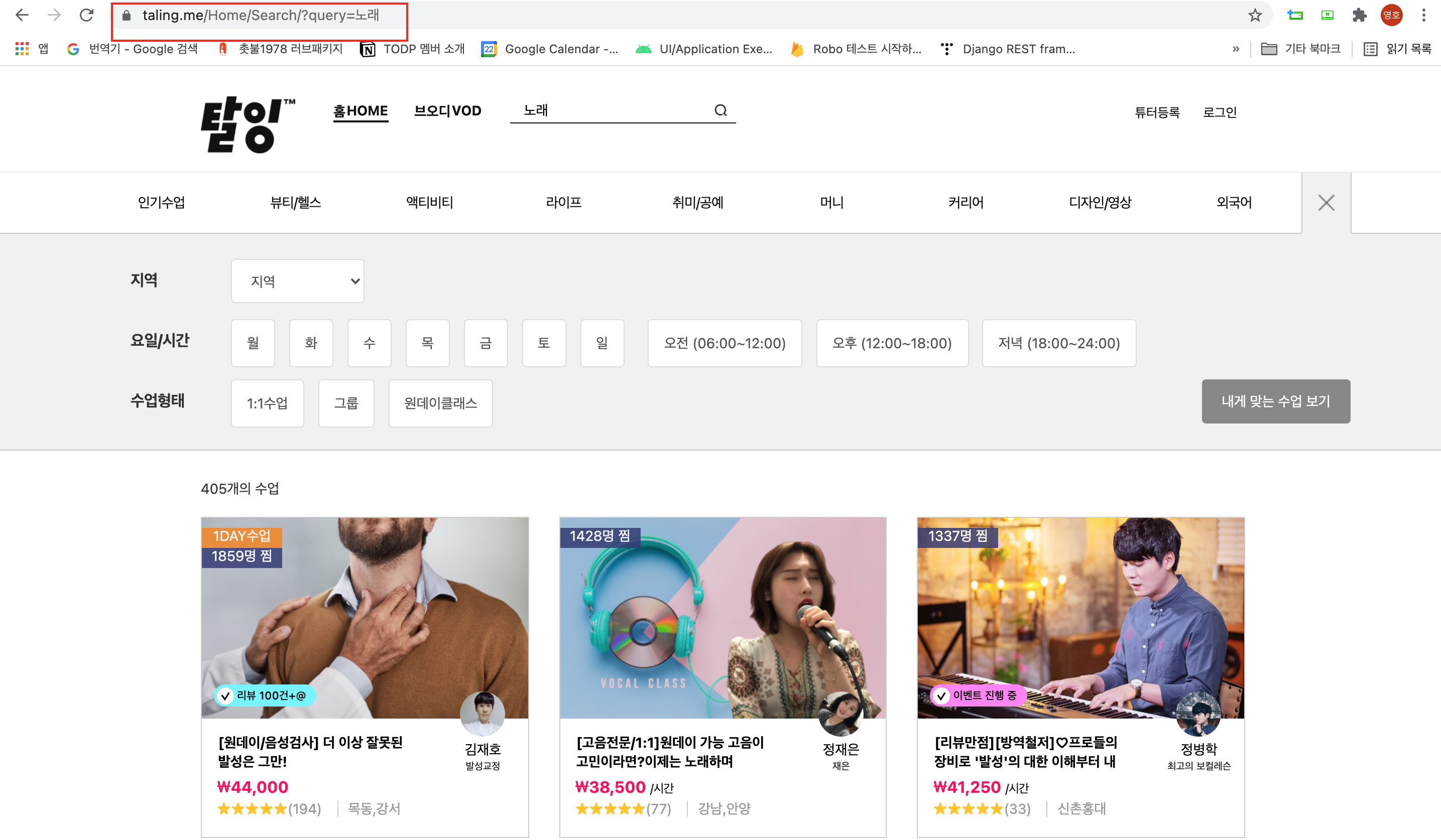
[https://taling.me/Home/Search/?query=노래] >> 해당 Url로 페이지가 조회된다. 이때, [query=] 해당 쿼리뒤에 아무 문자도 적지 않으면 전체 강의가 조회된다는 것을 발견했다!!!! 역시 인생은 잔머리!
더 분석을 해본 결과 Class101때와는 다르게 하단으로 스크롤링 할때마다 강좌가 더 조회되는 것이 아니라, 하단의 페이지 넘버가 존재한다. 한 페이지에 15개의 강좌가 조회되고 다음 번호를 누를때 마다 15개씩 반복적으로 조회된다.
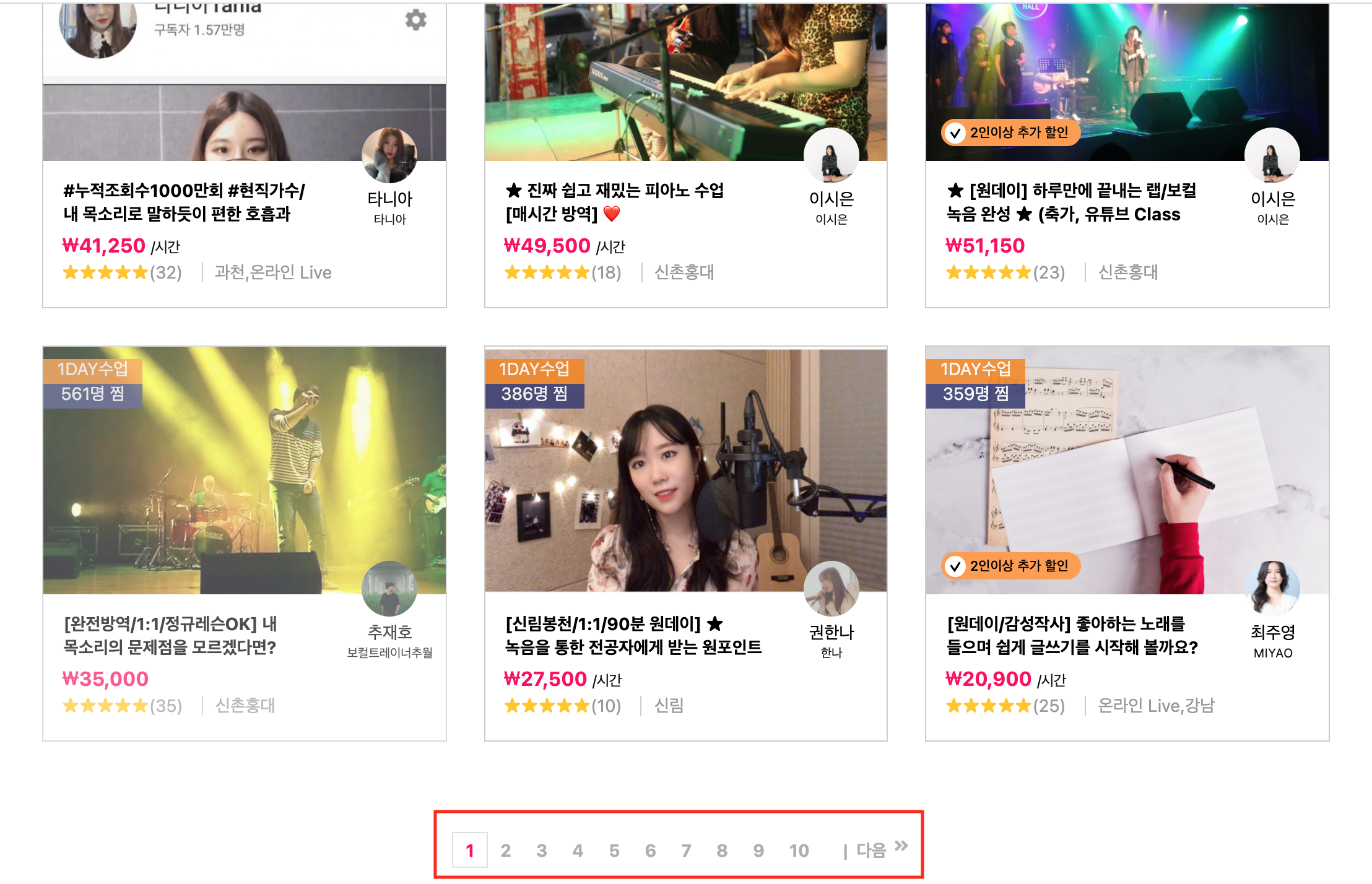
그 후, 이제 조회할 데이터를 분석하였다.
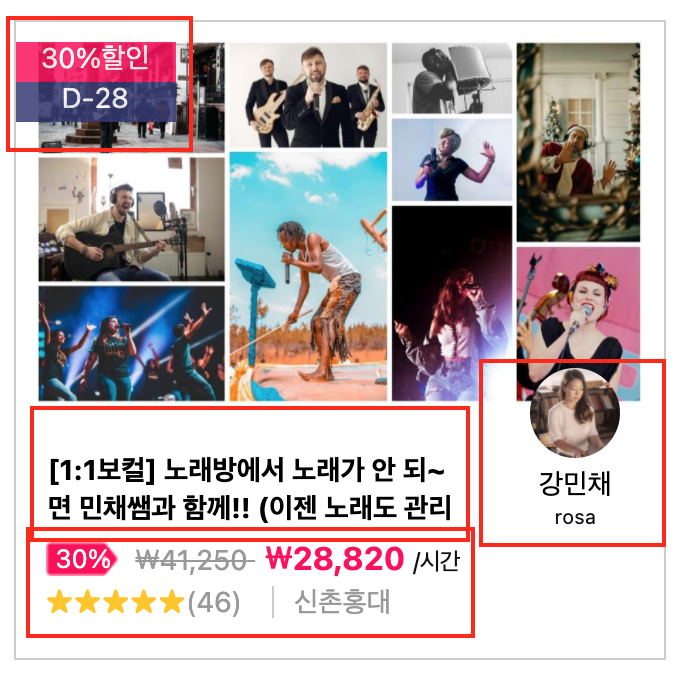
1. 할인률
2. 강좌명
3. 원가, 할인 가격, 강의 방식(시간당)
4. 강의 위치
5. 별점
6. 강사 정보
이러한 데이터가 조회가능하다! 자 이제 크롤링 시자아아악!!!!!!
.....

1번부터 6번까지 데이터에 강좌별 카테고리 데이터가 없다! 쓸모 없는 데이터가 되버려따.. 어떻하지....
두번째 시도
마음을 가다듬고 다시한번 페이지를 분석해 보았다.
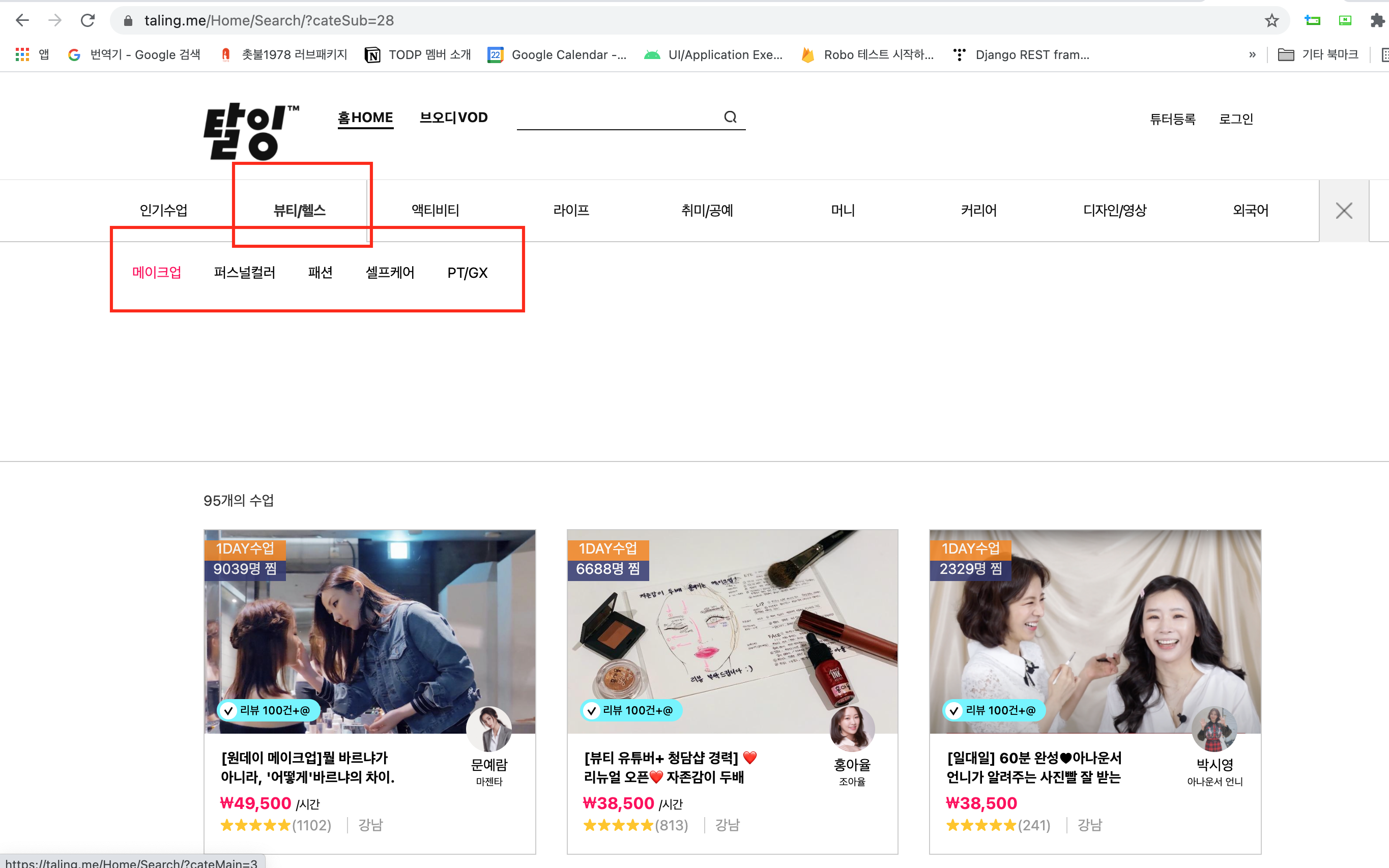
상단에 커다란 대메뉴(뷰티/헬스)가 있고 그 아래 소메뉴(메이크업/퍼스트컬러/패션/셀프케어...등)이 있고 해당 소메뉴를 클릭하면 그 메뉴에 맞는 데이터가 조회된다. 즉 카테고리 별로 강좌의 조회할려면 해당 방법으로 메뉴들을 클릭하면서 조회한 후, 저장을 해야한다는 것이다.
자, 이제 다시 개발할 내용을 정리해 보았다.
1. 한페이지당 15개씩 조회되는 강좌를, 마지막 페이지 까지 자동으로 넘어가면서 데이터를 수집하는 코드
2. 상단의 존재하는 대메뉴 > 소메뉴를 자동으로 클릭 및 이동하는 소스 코드
1번의 경우 첫시도 시 개발을 다 했음으로... 2번만 개발 하면된다!

개발환경
- MAC OS Big Sur 11.2.3
- Python3
- Chrome 버전 90.0.4430.93(공식 빌드) (x86_64)
- Chrome Driver 90.0.44
개발준비
사용한 패키지 및 도구
- selenium, BeautifulSoup, pandas
pip3 install selenium pip3 install BeautifulSoup pip3 install pandas
- ChromeDriver 설치 (자신이 로컬에 설치된 Chrome버전과 동일한 버전으로...)

개발내용
다시한번 알려드리지만 필자는 파이썬 개발자가 아님. 그리고... 하다가..너무 귀찮아서 코드질이 많이 많이 떨어진다... 눈갱 주의
전체 소스 코드(펼치기 시 스크롤 압박 주의 ;;;;)
# 목표 - 탈잉에 등록된 모든 강의들의 정보(클래스 명, 카테고리, like, 가격, 정보 등)
# https://taling.me/Home/Search/?query= 접속 시, 전체 강의목록을 조회할 수 있다.
# 한 화면에 15개의 강의가 나오게 되고, 하단 다음 페이지 번호를 눌러서 15개씩 조회가 가능하다.
# 따라서 현재 화면의 15강의씩 가장 마지막 페이지 번호까지 넘어가면서 저장을 해야함.
# 단순 화면의 강의 데이터로는 카테고리 분류가 불가능한 상황임 > 상단 메뉴를 옮겨 가면서 카테고리 데이터를 가져와야함.
from selenium import webdriver
import time
import re
from bs4 import BeautifulSoup
import pandas as pd
from selenium.webdriver.common.action_chains import ActionChains
#####상수#####
#뷰티/헬스 - sub1 , #cate2
#액티비티 - sub2 , #cate3
#라이프 - sub3 , #cate4
#취미/공예 - sub4 , #cate5
#머니 - sub5 , #cate6ㅣ,ㅣㅏ,,ㅏㅣㅡㅓㅏ mkkkkkkk
#커리어 - sub6 , #cate7
#디자인/영상 - sub7 , #cate8
#외국어 - sub8 , #cate9
# 하위 메뉴 선택시 sub로 시작하는 숫자 시작과 #cate 숫자 시작값이 달라서 이를 보정하기 위한 상수
MATCH_FOR_CATE_AND_SUB_NUMBER = 1
TEMP_SAVE_POINT = 100
# 전체 수강 강좌 조회 사이트 열기.
driver = webdriver.Chrome("./chromedriver")
driver.get('https://taling.me/Home/Search/?query=')
time.sleep(3)
pageNumber = [0,1,2,3,4,5,6,7,8,9,10,11,12]
goNextCss = '#container > div.main3_cont > div.page > a:nth-child'
moveCategoriQuery = '//*[@id="sub@subNumber"]/div/li[@childNumber]/a'
#'#sub@subNumber > div > li:nth-child(@childNumber) > a'
# str.replace('@subNumber', '8')
# str.replace('@childNumber', '1')
result = [ ]
subList = []
cateList = []
currentSubName = ''
currentSubCate = ''
######################## 전체 메뉴 및 메뉴 이동 관련 로직 ###########################
#메뉴 클릭 로직 정리
# action = ActionChains(driver)
# driver.find_element_by_css_selector('#cate2').click() # 큰 메뉴 클릭 한 후
# action.move_to_element(driver.find_element_by_css_selector('#cate2')).perform() # 마우스 올리고
# driver.find_element_by_css_selector('#sub1 > div > li:nth-child(4) > a').click() # 소메뉴 클릭
#전체 메뉴 리스트 (큰 subList) 가져오기
def getSubMenuList():
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
_subList = soup.select('li.cate > a > div')
numOfSub = len(_subList)
for i in range(numOfSub):
subList.append(_subList[i].text.strip())
print(subList)
def setcurrentSubName(idx):
currentSubCate = subList[idx]
# 전체 소메뉴? 카테고리 조회
def getCategori():
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
sublen = len(subList)
for i in range(sublen) :
cate = soup.select('#sub' + str(i) + ' > div > li')
catelen = len(cate)
for j in range(catelen):
cateList.append(cate[j].text)
print(cateList)
#소메뉴 갯수 가져오기
def getLenCategoriInSub(subIdx):
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
cate = soup.select('#sub' + str(subIdx) + ' > div > li')
return len(cate)
#대메뉴 이동
def clickSubMenu(idx):
global currentSubName
try:
driver.find_element_by_css_selector('#cate'+ str(idx + MATCH_FOR_CATE_AND_SUB_NUMBER)).click() # 큰 메뉴 클릭 한 후
except:
saveFile()
time.sleep(0.5)
####메뉴위로 마우스 이동 하기
action = ActionChains(driver)
action.move_to_element(driver.find_element_by_css_selector('#cate' + str(idx + MATCH_FOR_CATE_AND_SUB_NUMBER))).perform() # 마우스 올리기
currentSubName = driver.find_element_by_css_selector('#cate'+ str(idx + MATCH_FOR_CATE_AND_SUB_NUMBER)).text
print('************************************** currentSubName>>>>>>> ' + currentSubName)
time.sleep(0.5)
#소메뉴 이동
def clickCate(subNum, cateNum):
global currentSubCate
base = moveCategoriQuery
base = base.replace('@subNumber', str(subNum))
base = base.replace('@childNumber', str(cateNum))
print('Move Cate Query>>>>>>>>>>>>> ' + base)
try:
currentSubCate = driver.find_element_by_xpath(base).text
print('currentSubCate >>>>>> '+ currentSubCate)
except:
saveFile()
try:
driver.find_element_by_xpath(base).click()
except:
saveFile()
time.sleep(0.5)
def saveFile():
global result
_result = pd.DataFrame(result)
_result.to_csv('/Users/kimyoungho/python/taling.csv', index=False, encoding="utf-8-sig")
################################################데이터 수집 소스 코드 #############################################
#아래 3개는 존재할 수도 없을 수도 있으니 예외처리 필수임.
# soup.select('div.cont2 > div')[0].select('div.day')[0].text '1DAY수업'
# soup.select('div.cont2 > div')[0].select('div.d_day')[0].text.strip() 'D-50'
# soup.select('div.cont2 > div')[0].select('div.soldoutbox')[0].text.strip() 'SOLDOUT'
# soup.select('div.cont2 > div')[0].select('div.sale')[0].text '50%할인'
# soup.select('div.cont2 > div')[0].select('span.reward_badge')[0].text '30일 무료코칭' , 리뷰 100건
# soup.select('div.cont2 > div')[0].select('div.title')[0].text.strip() '[재무설계/저축/재테크/투자/주식] 미래설계를 위해 "돈"을 알려드립니다'
# soup.select('div.cont2 > div')[0].select('div.name')[0].text '나종길' 이름
# soup.select('div.cont2 > div')[0].select('div.nick')[0].text '미래설계사' 닉네임
####가격 데이터
# soup.select('div.cont2 > div')[0].select('div.price1')[0].text.strip() '\n₩11,000\n'
# soup.select('div.cont2 > div')[0].select('div.price2')[0].text.strip() '\n₩5,500\n'
# soup.select('div.cont2 > div')[0].select('div.price > div.sale')[0].text.strip() '50%'
# soup.select('div.cont2 > div')[0].select('span.hour_unit')[0].text '/시간'
#########평점 평가수 지역
# soup.select('div.cont2 > div')[0].select('div.info2 > div.star')[0].text.strip() '★★★★★'
# soup.select('div.cont2 > div')[0].select('div.info2 > div.review')[0].text.strip() '(26)'
# soup.select('div.cont2 > div')[0].select('div.info2 > div.location')[0].text.strip() '온라인 Live'
# 현제 화면에 15개의 강의데이터 뽑는 쿼리.
#soup.select('div.cont2 > div')
def setClassList(driver, result) :
global currentSubCate
global currentSubName
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
classList = soup.select('div.cont2 > div')
numOfClass = len(classList)
classPeriod = ''
classDday = ''
classSale = ''
classReward = ''
classSoldout = ''
classTitle = ''
lectureName = ''
lectureNick = ''
originPrice =''
salePrice =''
saleRate = ''
classunit = ''
classStar = ''
classReview = ''
classLocation = ''
for i in range(numOfClass) :
try:
classPeriod = classList[i].select('div.day')[0].text
except:
classPeriod = ''
try:
classDday = classList[i].select('div.d_day')[0].text.strip()
except:
classDday = ''
try:
classSoldout = classList[i].select('div.soldoutbox')[0].text.strip()
except:
classSoldout = ''
try:
classSale = classList[i].select('div.sale')[0].text
except:
classSale = ''
try:
classReward = classList[i].select('span.reward_badge')[0].text
except:
classReward = ''
try:
classTitle = classList[i].select('div.title')[0].text.strip()
except:
classTitle = ''
try:
lectureName = classList[i].select('div.name')[0].text
except:
lectureName = ''
try:
lectureNick = classList[i].select('div.nick')[0].text
except:
lectureNick = ''
try:
originPrice = classList[i].select('div.price1')[0].text.strip()
except:
originPrice = ''
try:
salePrice = classList[i].select('div.price2')[0].text.strip()
except:
salePrice = ''
try:
saleRate = classList[i].select('div.price > div.sale')[0].text.strip()
except:
saleRate = ''
try:
classunit = classList[i].select('span.hour_unit')[0].text
except:
classunit = ''
try:
classStar = classList[i].select('div.info2 > div.star')[0].text.strip()
except:
classStar = ''
try:
classReview = classList[i].select('div.info2 > div.review')[0].text.strip()
except:
classReview = ''
try:
classLocation = classList[i].select('div.info2 > div.location')[0].text.strip()
except:
classLocation = ''
result.append([currentSubCate, currentSubName, classTitle, lectureName, lectureNick, classPeriod, classDday, classSale, classReward, originPrice, salePrice, saleRate, classunit, classStar,classReview, classLocation, classSoldout])
# result.append(classList[i])
print(len(result))
global TEMP_SAVE_POINT
if len(result) > TEMP_SAVE_POINT:
print('temp save >>>>>>>>>>>>')
saveFile()
TEMP_SAVE_POINT = TEMP_SAVE_POINT + 1000
# 하단에 화면 번호를 클릭하는 쿼리
# 첫화면은 a:nth-child(2) 의 번호가 2 > 3 > 4 .... > 10 > 11(11은 다음으로)
# 그 다음부터는 "이전 버튼이 활성화 되어서" 3 > 4 > 5 > 6 ... > 11 > 12 (12는 다음으로)
# 위와 같은 형식으로 조회가 돠어야 함.
# 다음 조회목록으로 이동하기 위해 클릭하는 로직.
# driver.find_element_by_css_selector('#container > div.main3_cont > div.page > a:nth-child(2)').click()
def nextList(idx,driver):
try:
nextButton = driver.find_element_by_css_selector(goNextCss + '(' + str(pageNumber[idx]) + ')')
except:
return True
nextButton.click()
time.sleep(2)
return False
def getBottomPageNum() :
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
return len(soup.select('div.page > a'))
def startCrawling():
pageNum = getBottomPageNum()
if pageNum < 11 :
for i in range(2, 2 + pageNum):
setClassList(driver, result)
nextList(i,driver)
else :
#첫페이지만 따로 10번 돌린다... 인덱스가 달라서
#TODO 처음 페이지 수가
for i in range(2, 12):
setClassList(driver, result)
nextList(i,driver)
goNextCssNumber = 3
while(1):
setClassList(driver, result)
if(nextList(goNextCssNumber,driver)) :
break
else :
goNextCssNumber = goNextCssNumber + 1
if(goNextCssNumber > 12) :
goNextCssNumber = 3
print("Crawling Complete....")
# time.sleep(2)
##################################### Main Code ##################################################
getSubMenuList()
getCategori()
numOfSumList = len(subList)
for subMenuNum in range(1, numOfSumList):
print('NumOf MENU>>>>>>>>>>' + str(subMenuNum))
cateLen = getLenCategoriInSub(subMenuNum)
clickSubMenu(subMenuNum)
for cate in range(1, 1 + cateLen):
clickCate(subMenuNum, cate)
startCrawling()
saveFile()
간략하게 로직을 ... 아니 절대 간략하지 않다!
1. 탈잉에 접속한다.
2. 대 메뉴 클릭 > 대 메뉴 위에 마우스 오버
3. 소 메뉴 클릭
4. 15개의 강좌 크롤링 > 다음 페이지 넘기기 반복
5. 다음 소 메뉴 or 대 메뉴 클릭
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 이것만 보면 아주 단순해 보인다...하지만 ㅠㅠㅠㅠㅠㅠ 쉽지 않았다. 아니 솔직히 어렵지는 않았는데.. 노가다가 엄청 났다.
[2. 대 메뉴 클릭 > 대 메뉴 위에 마우스 오버] 해당 로직의 경우 좀 설명이 필요한게...

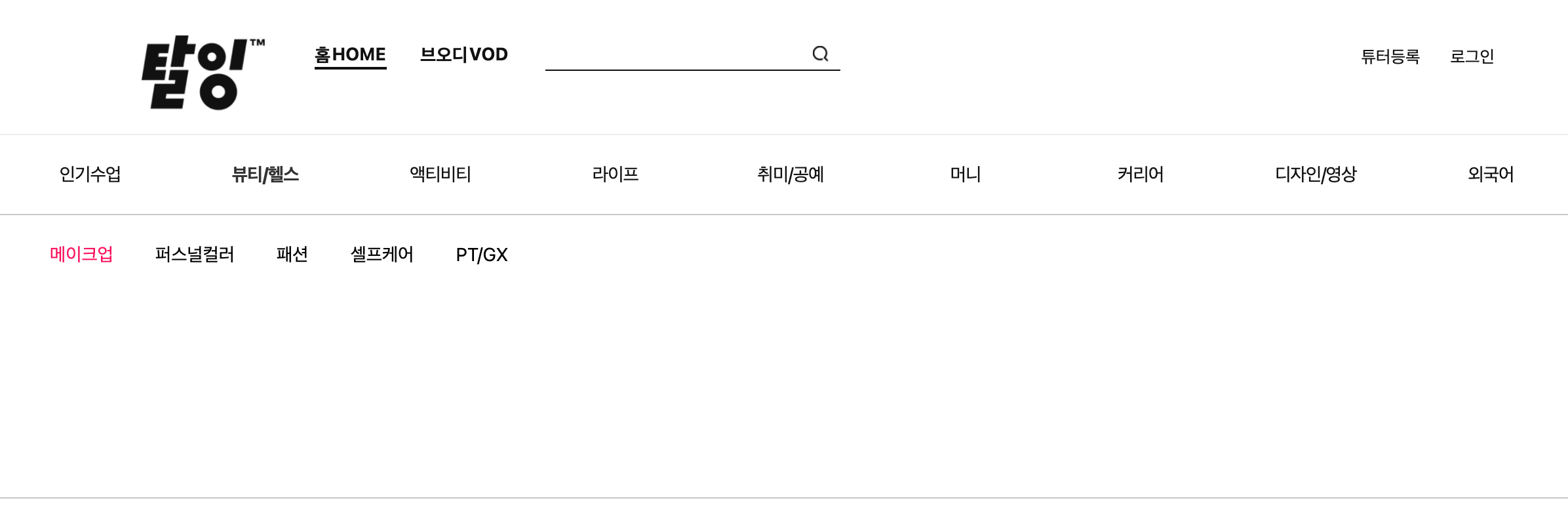
두 이미지를 봐보자. 차이는 첫 번째 화면은 필터 기능을 제공한다는 것이고 두번째 이미지는 소 메뉴가 보인다는 것이다.
마우스가 대메뉴 위에 있을때 Drop Down으로 소메뉴가 화면에 보이게 되고 다른 곳을 클릭하면 필터링 기능을 제공한다.
이때 문제가 발생하는것이.. 우리는 소메뉴를 클릭을 해야한다. 하지만 소메뉴가 화면에 나타나지 않을 경우
"selenium.common.exceptions.ElementNotInteractableException: Message: element not interactable"
이러한 오류에 마딱트리고 만다. 즉 화면에 보이는 Element만 클릭이 가능하다는 것이다. 그러기 위해서는 클릭 전에 대메뉴에 마우스를 올려서 소메뉴가 보이도록 해야한다는 말이다..그러한 로직을 구현한게 아래 부분이다.
#대메뉴 이동
def clickSubMenu(idx):
global currentSubName
try:
driver.find_element_by_css_selector('#cate'+ str(idx + MATCH_FOR_CATE_AND_SUB_NUMBER)).click() # 큰 메뉴 클릭 한 후
except:
saveFile()
time.sleep(0.5)
####메뉴위로 마우스 이동 하기
action = ActionChains(driver)
action.move_to_element(driver.find_element_by_css_selector('#cate' + str(idx + MATCH_FOR_CATE_AND_SUB_NUMBER))).perform() # 마우스 올리기
currentSubName = driver.find_element_by_css_selector('#cate'+ str(idx + MATCH_FOR_CATE_AND_SUB_NUMBER)).text
print('************************************** currentSubName>>>>>>> ' + currentSubName)
time.sleep(0.5)그리고 메뉴 이동의 경우 버튼들의 Xpath를 분석해 보니 아래 규칙으로 움직이는 것을 파악했다.
moveCategoriQuery = '//*[@id="sub@subNumber"]/div/li[@childNumber]/a'
# str.replace('@subNumber', '8') 해당 데이터를 replace해가면서 이동
# str.replace('@childNumber', '1') 해당 데이터를 replace해가면서 이동
실행결과
크롤링 하는 로직을 제외하고 화면 이동 하는 것만 동영상으로 찍어 봤다. 해당 방식으로 메뉴를 이동하면서 데이터를 가져오는 것이다.
나도 처음 해보는거라서...진짜 신기하긴 했다. 이렇게 크롤링을 하니 수집한 데이터를 대메뉴 > 소메뉴 별로 나눌 수 있었다.
마무리
점점...크롤링 실력이 늘어가는 것은 착각인가...?
이번 탈잉 사이트를 크롤링하면서 다른 사이트보다 훨씬 강좌수가 많이 있다는것에 놀랐다. 다른 사이트보다 강좌들이 온라인 보다 오프라인 위주라는 것, 원데이 클래스가 많이 있다는 것도 알게 되었다. 그리고...이제 또 그 많은 데이터들로 어떠한 유의미한 정보를 파악할 수 있을지도 스터디 중(사실 이것부터 시작이다)
사이트를 보니 약 6500개의 강좌가 있는거 같은데... 내가 크롤링한 데이터는 6000개 정도 이다..(500개 어디 갔지???)

이번에 작성한 프로그램 정확도가 100프로도 아니고, 코드 질도 많이 떨어 지지만... 그래도 결과 자체는.. 나름 너무 뿌듯 >_< 헤헤
시간 날때 천천히 코드 질도 올리고 사라진 500개의 데이터도 찾아 봐야겠다... 찡긋 >_o